1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
| from tqdm import tqdm
import pickle as pkl
import torch
import sys
import time
import os
def train_val(net, optimizer, n_epochs, trainBS, valBS, trainDataset, trainLoader, valDataset, valLoader, expLrScheduler, modelPath, modelName):
"""
net (torchvision.models) : Net model for training/validation
optimizer (torch.optim) : Optimizer for training
n_epochs (int) : Training epochs
trainBS (int) : Training batchsize
valBS (int) : Validation batchsize
trainDataset (torch.Dataset)
trainLoader (torch.DataLoader)
valDataset (torch.Dataset)
valLoader (torch.DataLoader)
expLrScheduler (torch.optim.lr_scheduler) : Learning rate decay strategy
modelPath (str) : Path to save the learnt model
modelName (str) : Model name
"""
lossLog = dict({'train': [], 'val': []})
accLog = dict({'train': [], 'val': []})
dataSet = {'train': trainDataset, 'val': valDataset}
dataLoader = {'train': trainLoader, 'val': valLoader}
dataSize = {x: dataSet[x].__len__() for x in ['train', 'val']}
batchSize = {'train': trainBS, 'val': valBS}
iterNum = {x: np.ceil(dataSize[x] / batchSize[x]).astype('int32') for x in ['train', 'val']}
print('dataSize: {}'.format(dataSize))
print('batchSize: {}'.format(batchSize))
print('iterNum: {}'.format(iterNum))
best_acc = 0.0
start = time.time()
for epoch in tqdm(range(n_epochs), desc='Epoch'):
print('Epoch {}/{}, lr = {} [best_acc = {:.4f}%]'.format(epoch+1, n_epochs, optimizer.param_groups[0]['lr'], best_acc))
print('-' * 10)
epochStart = time.time()
for phase in ['train', 'val']:
if(phase == 'train'):
expLrScheduler.step()
net.train()
else:
net.eval()
losses = AverageMeter()
top1 = AverageMeter()
for i, data in enumerate(dataLoader[phase], 0):
inputs, labels = data
inputs = inputs.cuda()
labels = labels.cuda()
with torch.set_grad_enabled(phase == 'train'):
outputs = net(inputs)
loss = criterion(outputs, labels)
if(phase == 'train'):
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.update(loss.item()*inputs.size(0), inputs.size(0))
sys.stdout.write(' \r')
sys.stdout.flush()
prec1 = accuracy(outputs, torch.argmax(labels, 1), topk=(1,))[0]
top1.update(prec1.item(), inputs.size(0))
sys.stdout.write('Iter: {} / {} ({:.0f}s)\tLoss= {:.4f} ({:.4f})\tAcc= {:.2f}% ({:.0f}/{:.0f})\r'
.format(i+1, iterNum[phase], time.time() - epochStart, loss.item(), losses.avg, prec1/inputs.size(0)*100, top1.sum, top1.count))
sys.stdout.flush()
sys.stdout.write(' \r')
sys.stdout.flush()
epoch_loss = losses.avg
epoch_acc = top1.avg*100
accLog[phase].append(epoch_acc/100)
lossLog[phase].append(epoch_loss)
epochDuration = time.time() - epochStart
epochStart = time.time()
hour, minute, second = convert_secs2time(epochDuration)
print('[ {} ] Loss: {:.4f} Acc: {:.3f}% ({:.0f}/{:.0f}) ({:.0f}h {:.0f}m {:.2f}s)'
.format(phase, epoch_loss, epoch_acc, top1.sum, top1.count, hour, minute, second))
if(phase == 'val' and epoch_acc > best_acc):
print('Saving best model to {}'.format(os.path.join(modelPath, modelName)))
state = {'net': net.state_dict(), 'opt': optimizer, 'acc': epoch_acc, 'epoch': epoch, 'classes': classes}
torch.save(state, os.path.join(modelPath, modelName))
best_acc = epoch_acc
if(phase == 'val' and epoch == n_epochs - 1):
finalModelName = 'final-{}'.format(modelName)
print('Saving final model to {}'.format(os.path.join(modelPath, finalModelName)))
state = {'net': net.state_dict(), 'opt': optimizer, 'acc': epoch_acc, 'epoch': epoch, 'classes': classes}
torch.save(state, os.path.join(modelPath, finalModelName))
print('')
log = dict({'acc': accLog, 'loss': lossLog})
with open(os.path.join(modelPath, 'log.pkl'), 'wb') as f:
pkl.dump(log, f)
if(epoch + 1 == n_epochs):
print("Training logs saved to : {}".format(os.path.join(modelPath, 'log.pkl')))
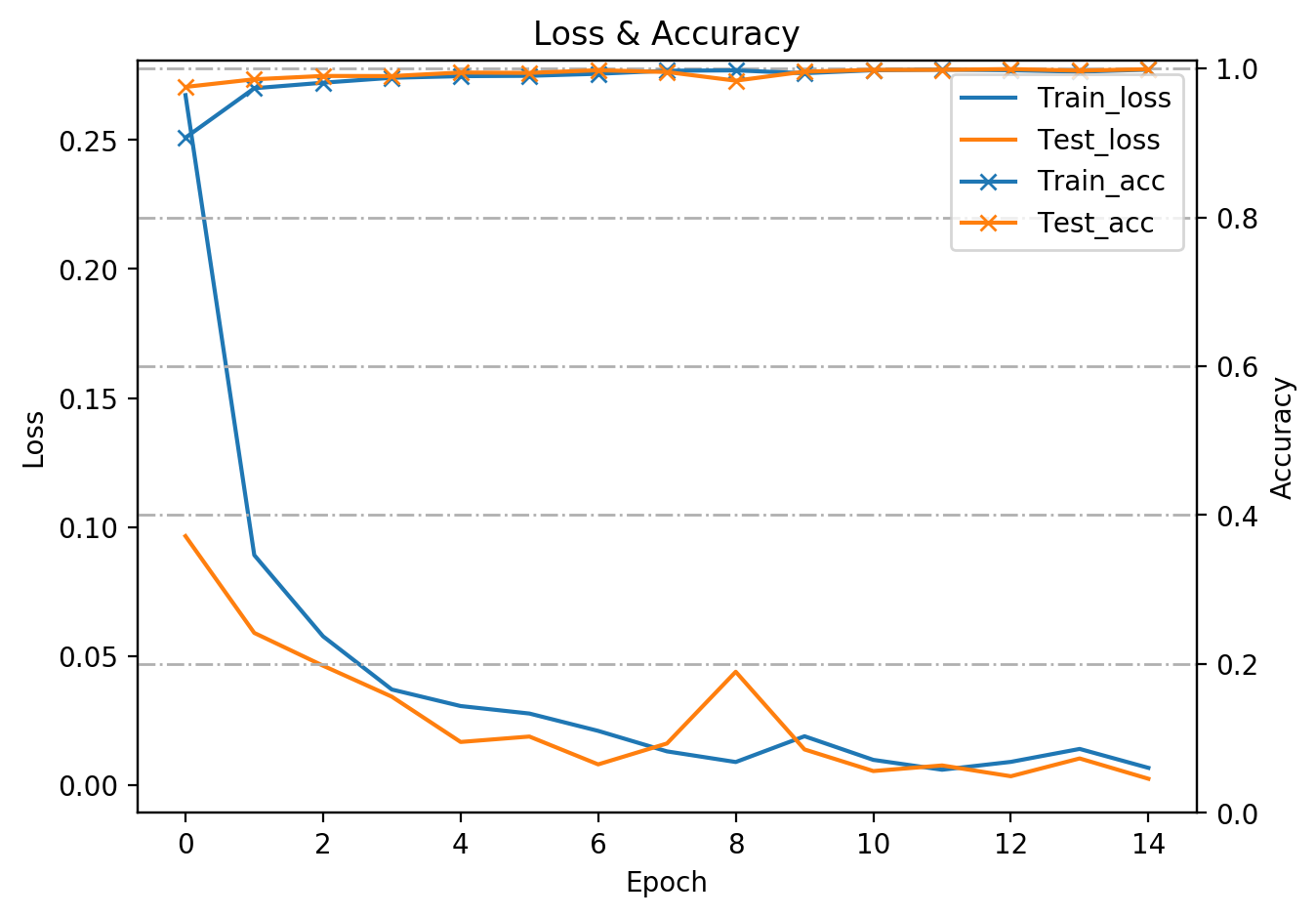
plot_acc_loss(log, 'both', modelPath, '{}_'.format(modelName), '', (epoch + 1 == n_epochs))
plot_acc_loss(log, 'loss', modelPath, '{}_'.format(modelName), '', (epoch + 1 == n_epochs))
plot_acc_loss(log, 'accuracy', modelPath, '{}_'.format(modelName), '', (epoch + 1 == n_epochs))
duration = time.time() - start
print('Training complete in {:.0f}h {:.0f}m {:.2f}s'.format(duration // 3600, (duration % 3600) // 60, duration % 60))
print('Best val Acc: {:4f}'.format(best_acc))
return best_acc
trainBS = 100
testBS = 100
myTransform = transforms.Compose([
transforms.ToTensor(),
])
trainDataset = myDataset(trainImage, torch.Tensor(trainLabel).long(), classes, transform=myTransform, to_onehot=True)
trainLoader = DataLoader(trainDataset, batch_size=trainBS, shuffle=True, num_workers=8)
testDataset = myDataset(testImage, torch.Tensor(testLabel).long(), classes, transform=myTransform, to_onehot=True)
testLoader = DataLoader(testDataset, batch_size=testBS, shuffle=False, num_workers=8)
net = models.resnet18(pretrained=False)
fc_features = net.fc.in_features
net.fc = nn.Linear(fc_features, len(classes))
net.avgpool = nn.AdaptiveAvgPool2d((1, 1))
net = net.cuda()
lr = 0.1
momentum = 0.9
weightDecay = 5e-4
criterion = myLoss().cuda()
optimizer = optim.SGD(net.parameters(), lr=lr, momentum=momentum, weight_decay=weightDecay, nesterov=True)
expLrScheduler = optim.lr_scheduler.MultiStepLR(optimizer, [50, 75], gamma=0.1)
modelPath = 'xxxxxxxxxxxxxx/pytorch_model_learnt'
modelName = 'resnet18.ckpt'
best_acc = train_val( net,
optimizer,
10,
trainBS,
testBS,
trainDataset,
trainLoader,
testDataset,
testLoader,
expLrScheduler,
modelPath,
modelName)
|