什么是 Word2Vec
Word2Vec 实际上是 Word Embedding 的一种实现方式,用来将一个词(Word)嵌入到某个空间中,用一个唯一的向量(Vector)去表示它。在这个空间中,语义相近的两个 Word 所对应的 Vector 具有更近的距离,即向量的距离可以用来衡量单词间的予以相似程度。
Word vector 的一个很有意思的特性是,它支持算术运算,比如:。
Word2Vec 有什么用
说白了,Word2Vec 就是为了做 Word Embedding,而 Word Embedding 做的就是把文本变成向量。有了向量之后,才能进行后续多种多样的NLP任务,比如文本分类、情感分析、机器翻译、问答系统、阅读理解等。因此,Word Embedding 作为这一系列任务的基础,有着举足轻重的作用。而 Word2Vec 作为这一领域算是开创性的算法,为后来的一系列新方法奠定了基础,更是具有重要意义。
Word2Vec 的实现
说白了,Word2Vec 本质上就是一个简单的神经网络,包含一个输入层(Input Layer)、一个隐含层(Hidden Layer)和一个输出层(Output Layer)。我们去训练这么一个神经网络,与一般思路不同的是,最终需要的并不是这个 Model 本身,而是它隐含层中各个神经元的参数,这些参数就是我们需要去学习的东西,称之为词向量(Word vectors)。
Word2Vec 可分为两种实现方式:
- CBOW(Continuous Bag-of-Words):用上下文预测当前词。适合小型语料库。运算量小,效果稍差。
- Skip-Gram:用当前词预测上下文。适合大型语料库。运算量大,效果较好。
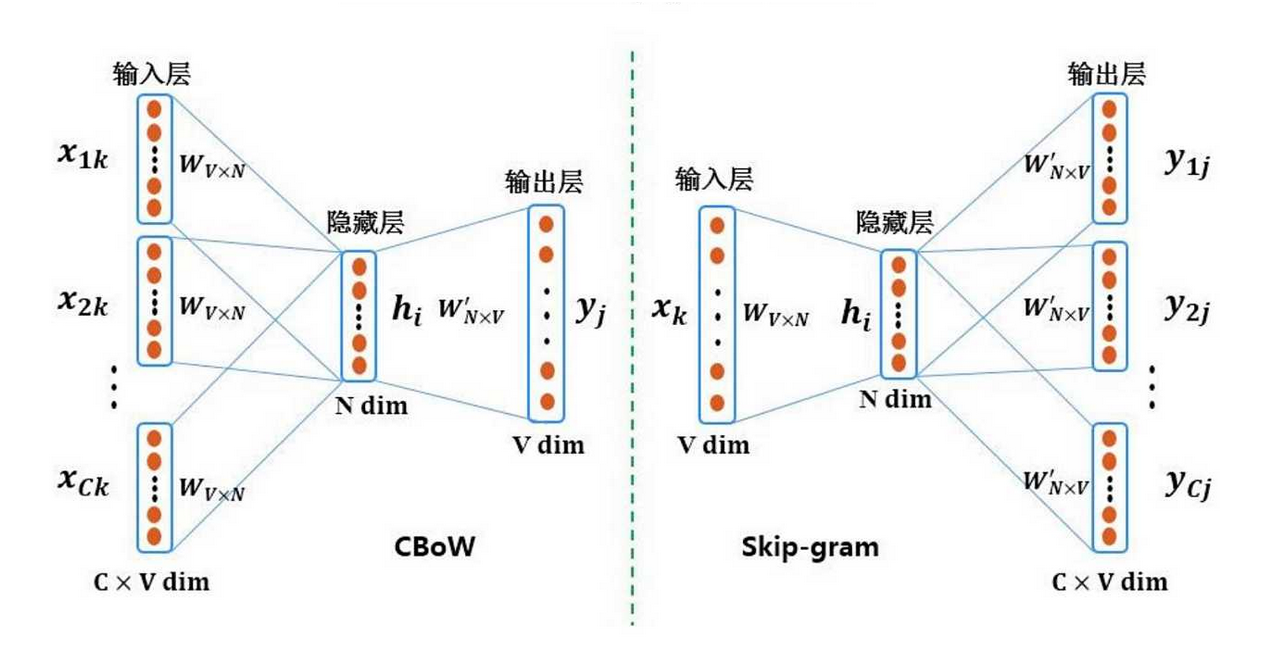
一个简单的 Skip-Gram 网络结构如图所示,本文中我们以此为例进行讲解。
我们的输入数据为Word pairs,比如对于一个句子“I drove my car to the store”,我们将“car”作为当前词,则根据“car”的上下文,我们可以构造如下 Word pairs(假设窗口长度为2):
- (“car”,“drove”)
- (“car”,“my”)
- (“car”,“to”)
- (“car”,“the”)
对于每个Word pair,我们将前者(“car”)送到输入层,并希望输出层的结果更接近于后者({“drove”,“my”,“to”,“the”}),如此构造损失函数,不断迭代训练模型。
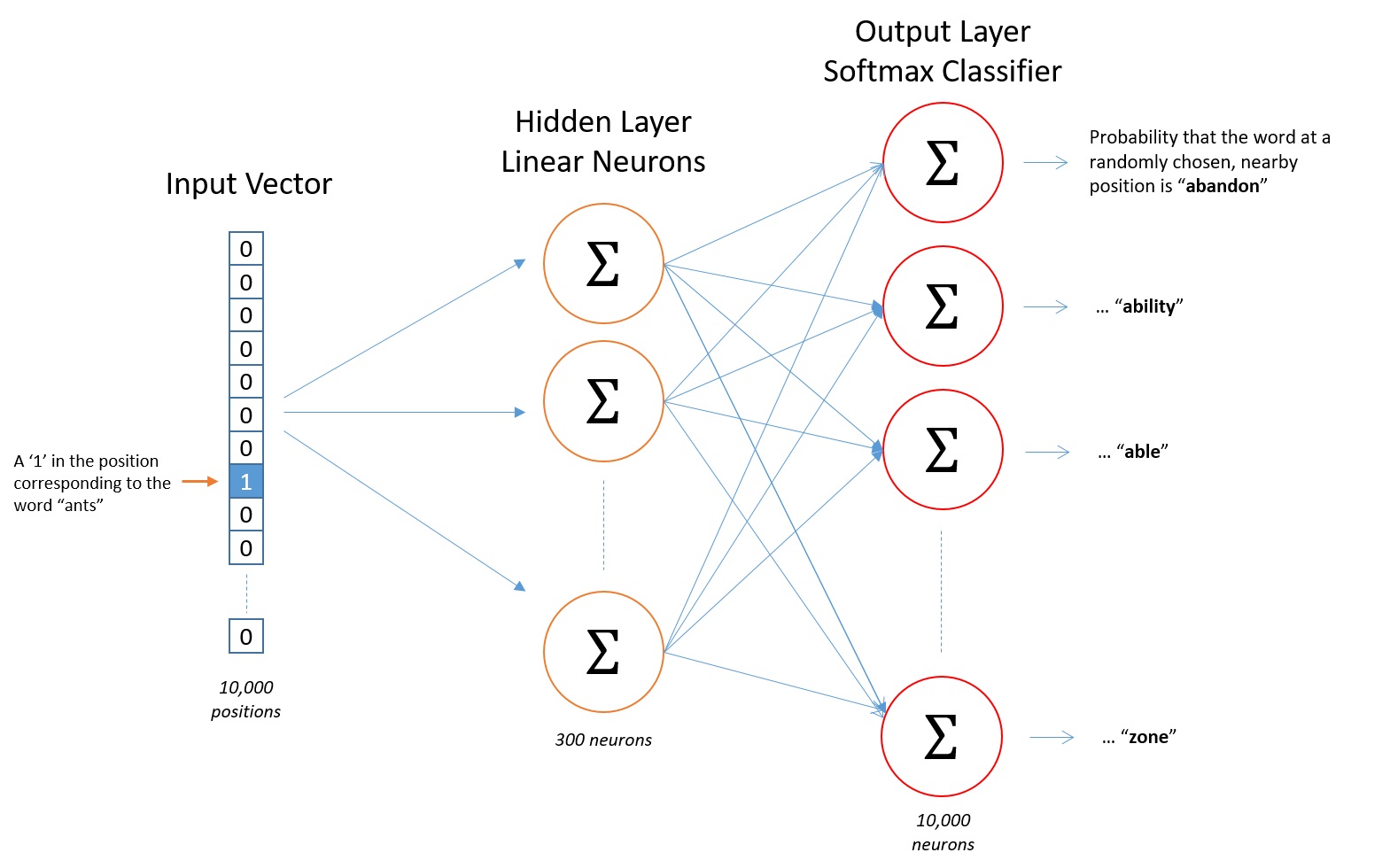
输入层
一个显而易见的事实是,我们不能直接把文本输入到神经网络中(比如不能直接把“apple”这个单词作为输入,因为神经网络并不知道这是啥),我们需要的是数值型数据,这里使用 One-Hot 编码来表示每一个词。
假设我们的词汇表(Vocabulary)中有10,000个不重复的词,输入的就是每个词对应的 One-Hot 编码,因此输入层维度为1x10,000。
隐含层
隐含层其实就是一个简单的全连接层(Fully Connected Layer),后面不接激活函数,本例中有300个神经元,表示每个 Word 将会提取出 300 个特征作为 Word vector,因此隐含层的参数就是一个 10,000 x 300 的矩阵,我们称之为 Weight Matrix,每一行表示一个 Word vector,如下图所示。
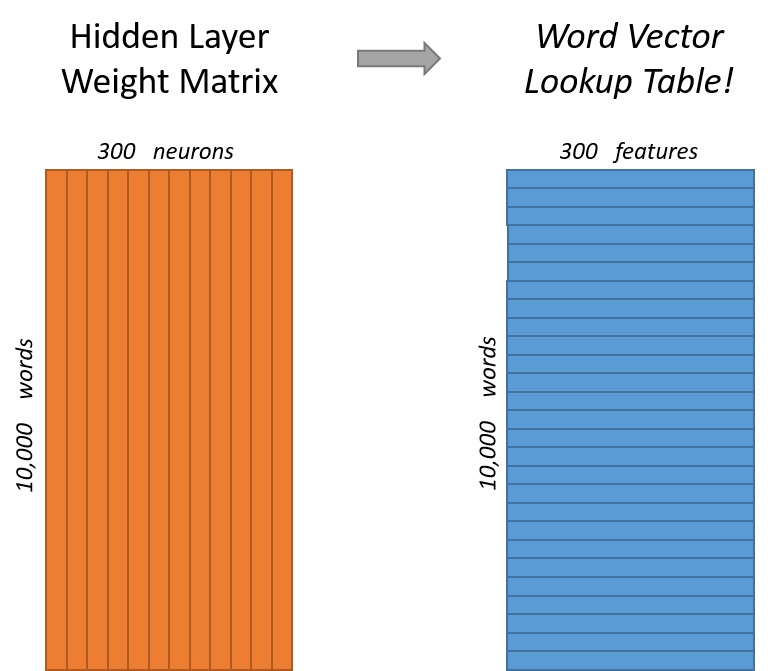
从中可以看出,这个参数矩阵实际上就是一个 Word vector 的查询表,比如我们输入词汇表中第4个词的 One-Hot 向量,将之与 Weight Matrix 相乘,即可得到第4个词所对应的 Word vector:
输出层
输出层也是一个维度为1x10,000的向量,经过一个 Softmax 层后,表示对于当前 Word ,这10,000个词中每个 Word 会随之出现的概率。
假设我们输入的是单词 “ants” 的 One-Hot 向量,经过隐含层后可以得到 “ants” 1x300的 word vector,下图展示了输出层的具体细节:
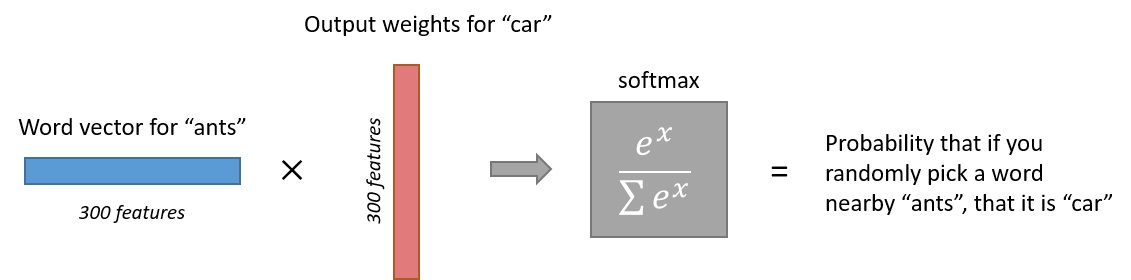
我们得到了1x10,000的 output 结果,假设词汇表中第123个词为“car”,第6666个词为“small”,那么根据常识,output 中第123个数值将会小于第6666个数值,因为相对于 “ants” 和 “car”,“ants” 和 “small” 具有更强的相关性,当出现 “ants” 时,上下文更有可能出现 “small” 而不是 “car”。
Word2Vec 做文本分类
- 训练好的 Word2Vec 模型
- 对每句句子执行以下操作:
- 分词
- 用 获取每个词的词向量
- 对一句话中的所有词向量求平均,作为这句话的 Sentence vector
- 后接一个分类器,进行监督学习。(每句话的 Sentence vector 和其对应的 label 作为一个训练样本)
Word2Vec 的改进
回顾上文,对于一个有10,000个单词的词汇表,当隐含层神经元个数为300个时,隐含层权重矩阵为 10,000x300,输出层权重矩阵为 300x10,000,也就是总计 6,000,000 个参数,而这只是对于一个输入数据来说的,当我们有数十亿个输入数据,这计算量不容小觑。因此 Word2Vec 的作者们在他们第二篇论文中提出了两点改进之处:
- Subsampling:只采样出现频率高的词,以此来减少计算量。
- Negative Sampling:调整训练策略,让每个训练样本只更新部分模型参数。
这两点改进不仅极大地减少了计算量,而且还提高了 Word vectors 的质量。
Subsampling
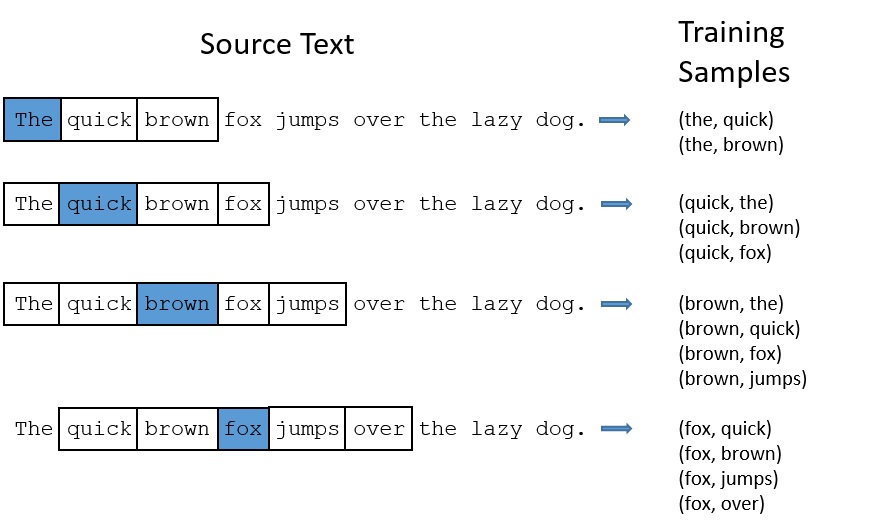
以上图的 Skip-gram 模型为例,我们设滑动窗口长度为2,即以当前词作为输入,其前后两个词作为输出,可以得到很多的训练样本对,我们会发现其中存在的问题:
- 与“the”相关的样本对非常多,但是却大多没有啥重要意义
- 与“the”相关的样本对过多,导致模型过于关注“the”
因此接下来我们就需要定义一个采样率(Sampling rate)来控制每个样本被采样到的频率。设 为某个 Word, 表示在一个语料库中 出现的次数除以语料库总词数。比如对于 “peanut” 这个次,假设它在语料库中共出现了1,000次,而语料库总共有10亿个词,则 。
另外一个参数称为“sample”,用来控制 Subsampling 的频率,默认为 0.001,值越小,表示词越不可能被保留。
令 表示要保留 这个词的可能性:
Negative Sampling
正常来说,我们训练神经网络时,每个样本将会作用于所有权重参数的更新过程,而Negative Sampling将更新的范围缩小到了一小部分权重,从而降低梯度下降过程中的计算量。
对于一个给定的词 ,它的上下文记为 ,那么 就是一个正例(Positive sample),剩下的 就是负例(Negative sample),但是负例太多了,负采样(Negative Sampling)就提出了一种选择合适的负例的方式。直觉上,根据“高频词被选中作为负例的概率更大”这一规则,可写出如下公式:
分子为 这个词在语料库中出现的次数,分母为语料库总词数。
Word2Vec 的作者们在他们的文章中指出,对词的计数取 次方,可以得到最好的 embedding 效果:
拓展
Doc2Vec
Doc2Vec 又称为 Paragraph2Vec 或者 Sentence Embedding,是在 Word2Vec 的基础上,用于将句子嵌入到某个空间中,表示成向量的形式。
应用场景:
- 文本聚类
- 文本分类
- 情感分析
- ……
类似于 Word2Vec 中的 CBOW 和 Skip-Gram 模型,Doc2Vec也分为两种实现方式,分别为PV-DM(Distributed Memory Model of paragraph vectors)和PV-DBOW(Distributed Bag of Words of paragraph vector),一一对应。
PV-DM
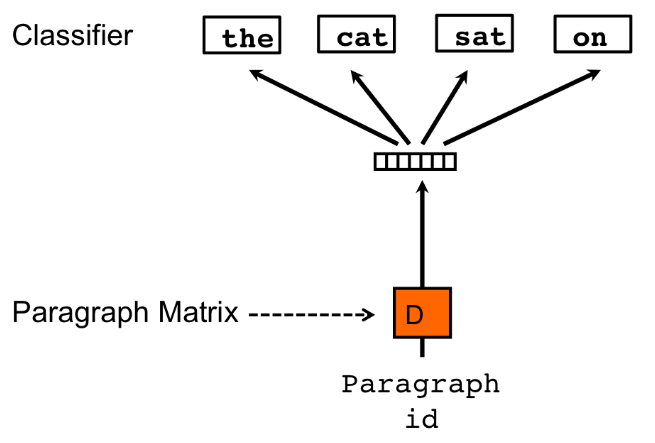
PV-DM结构如图所示:
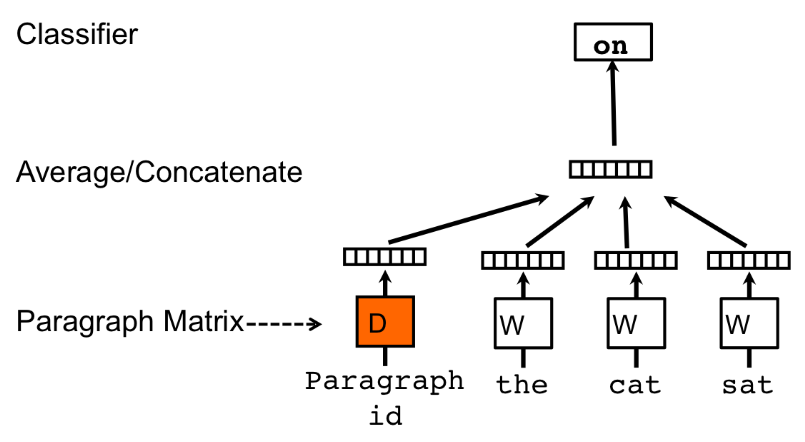
在Doc2Vec中,每一句话对应唯一的向量,用矩阵D的某一列来表示;每一个词也对应唯一的向量,用矩阵W的某一列来表示。其中的矩阵 D 和 W 类比到 Word2Vec 中的隐含层权重矩阵。
我们每次从一句话中滑动采样固定长度的一串词,取其中一个词 作为预测词,剩下的作为输入词。将输入词对应的 Word vector 和本句话对应的 Paragraph vector 作为输入层的输入数据,然后将它们相加求平均或者累加构成一个新的向量 ,我们用这个向量 来预测 。
相对于 Word2Vec 的不同之处在于,在输入层加了一个新的 Paragraph vector,它可以被看作是另一个 “Word vector”,扮演着一个“记忆”或者说“总结”的角色,每次训练的过程,都会让这个 Paragraph vector 所表达的主旨越来越准确。
PV-DBOW
PV-DBOW结构如图所示:
输入当前句子的 Paragraph vector,让它去预测句子中随机一个词。
FastText
一个字:快!
FastText是一个快速文本分类算法,与基于神经网络的相关算法相比具有如下优点:
- 在保持高精度的情况下加快了训练和测试速度
- 无需预训练好的词向量,可自己从头训练
- 两个关键 Contribution:Hierarchical Softmax、N-gram
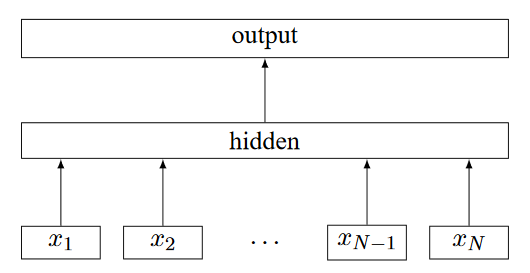
FastText 和 CBOW 模型十分相似,均由一个输入层、一个隐含层和一个输出层组成。CBOW 通过上下文的几个单词来预测中间单词;而FastText将一整个需要分类的句子整理成 N 个 N-gram特征,来预测这整个句子的类别。
Hierarchical Softmax
回顾一下 Word2Vec 模型中,输出层最后要经过一个 Softmax 运算,当类别很多时,计算量非常大,因此 FastText 提出了 Hierarchical Softmax 的思想,根据类别的频率构造 Huffman 树,可以将复杂度从 降低到 ,如下图所示:
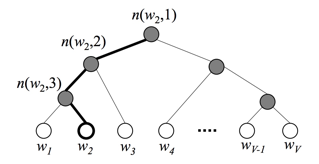
其中叶子结点 表示所有的词,我们要计算的是目标词 的概率,具体是指,从根节点开始随机走,一直走到 所经过的概率。因此我们还需要分别定义每个非叶子节点向左走和向右走的概率,其中 表示 Sigmoid 函数:
以上图中目标词为 为例:
整理一下,可以看出目标词为 的概率可以表示为:
其中 是非叶子节点 的向量表示; 是隐含层的输出; 是一个特殊的函数:
N-gram
在文本特征提取中,经常能看到 N-gram 的身影,他是一种基于语言模型的算法。其基本思想是将文本内容按照字节顺序进行大小为N的滑动窗口操作,从而形成长度为N的字节片段序列。看如下例子:
输入:
- 上海自来水来自海上
对应的 bigram(2-gram)特征为:
- 上海 海自 自来 来水 水来 来自 自海 还上
对应的 trigram(3-gram)特征为:
- 上海自 海自来 自来水 来水来 水来自 来自海 自海上
值得注意的是,N-gram 根据粒度的不同,具有不同的含义,比如字粒度、词粒度等,看如下使用词粒度的例子:
输入:
- 上海 自来水 来自 海上
对应的 bigram(2-gram)特征为:
- 上海/自来水 自来水/来自 来自/海上
对应的 trigram(3-gram)特征为:
- 上海/自来水/来自 自来水/来自/海上
而 FastText 中采用了字符粒度的 N-gram 来表示一个单词:
输入:
- apple
对应的 trigram(3-gram)特征为:
- “(ap”, “app”, “ppl”, “ple”, “le)”
其中,’(‘表示前缀,’)'表示后缀。于是,我们可以用这些trigram特征来表示“apple”这个单词,进一步地,我们可以用这5个trigram的向量叠加来表示“apple”的词向量。
优点:
- 可以为低频词生成更好的词向量
- 即使一个词没出现在训练语料库中,仍可以从字符粒度 N-gram 中构造该词的词向量
- 可以学习到局部单词顺序的部分信息
FastText vs. Word2Vec
| FastText | Word2Text | |
|---|---|---|
| 类型 | 有监督 | 无监督 |
| 目的 | 端到端文本分类,词向量是副产物 | 只是训练词向量 |
| 输入 | 一个句子的每个词和句子的N-gram特征 | 当前词或者上下文的词 |
| 输出 | 对句子的类别预测 | 对词的预测 |
实践
Word2Vec 以及 Doc2Vec 一般使用第三方库 gensim进行操作,可参考:
Reference
[1] Word2Vec Tutorial1: McCormick, C. (2016, April 19). Word2Vec Tutorial - The Skip-Gram Model
[2] Word2Vec Tutorial2: McCormick, C. (2017, January 11). Word2Vec Tutorial Part 2 - Negative Sampling
[3] 李宏毅课程: https://www.youtube.com/watch?v=X7PH3NuYW0Q
[4] FastText Tutorial: fastText原理及实践