BERT 是个啥
在 NLP 领域的一大挑战是训练数据的稀缺,因为 NLP 是一个非常大的多样化的领域,需要去处理许多独特的任务(如问答系统、情感分析等),而对于每个任务来说,其相关数据集只有几千或者几十万条已标注数据,而这对于基于深度学习的 NLP 模型来说是远远不够的。
因此,为了跨越这条鸿沟,BERT(Bidirectional Encoder Representations from Transformers) 便应运而生,它的一个高性能的、基于 Transformer Encoder 的 NLP 预训练模型,BERT 预先训练处一个对自然语言有一定“理解”的通用模型,然后任何人都能够针对不同的下游任务(如问答系统、情感分析等),用 BERT 在自己的数据集上进行微调(Finetune),从而提取到高质量的语言特征(即 Word & Sentence vectors),实现 SOTA 的预测效果。
BERT 强在哪
- Bidirectional Transformer
与 Word2Vec 等相关的算法相比,BERT 能够根据单词所处的上下文去动态地提取其语义信息,而 Word2Vec 及其相关算法对同一个单词具有固定的语义信息表示,这在一词多义的情况下就不合适了。
比如如下两个句子:
1、The man was accused of robbing abank.
2、The man went fishing by thebankof the river.前者与“robbing”相关,表示“银行”
后者与“river”相关,表示“河岸”BERT 有能力去分辨二者,而 Word2Vec 不行
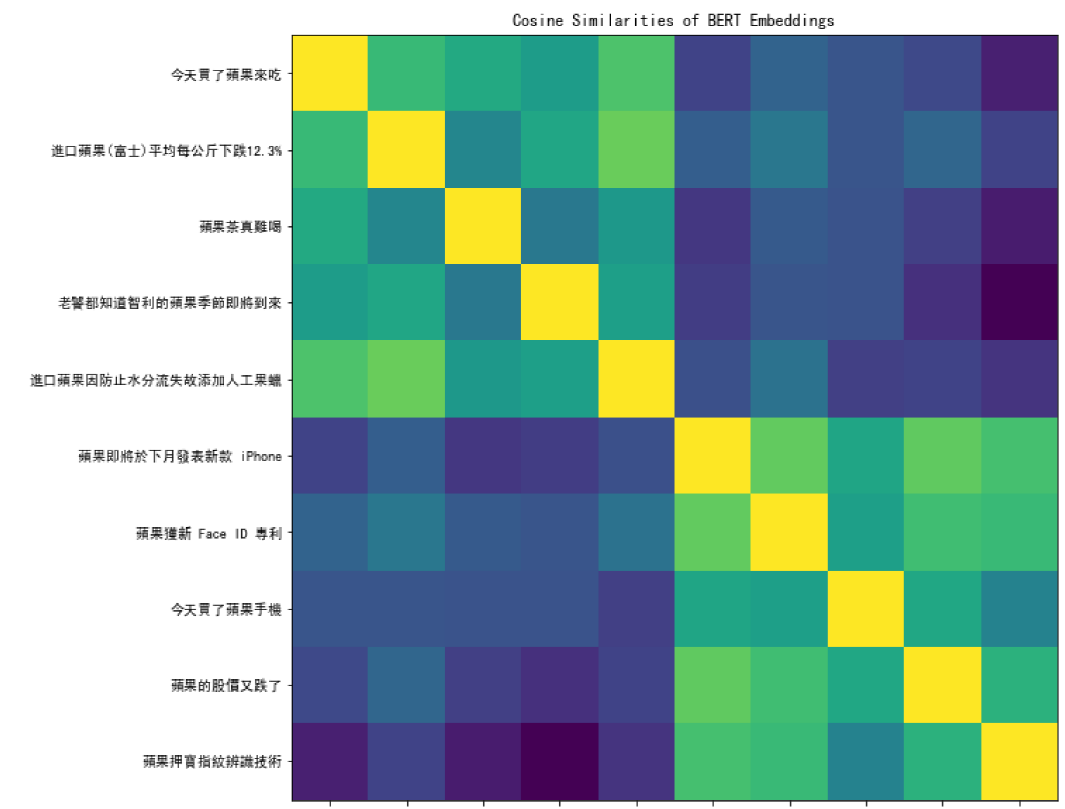
下图展示了 BERT 对不同语境中 “苹果” 这个词所提取到的 Embedding 两两之间的相似度矩阵,可见 BERT 在这方面的能力:
BERT 的网络架构
BERT 的网络架构实际上就是 Transformer 中的 Encoder 部分,即下图中的左半部分。
![]()
关于 Transformer 的知识点,可以参考视频或Blog来学习,这里简要介绍一下。Transformer 是一种注意力机制,可以学习文本中单词间的上下文关系。Transformer 的关键点在于一个叫做 Self-Attention Layer 的层,输入一个 Sequence,输出也是一个 Sequence,即Seq2Seq。
下面给出用 Transformer 做机器翻译的动图(来自Google AI Blog),帮助理解:
![]()
Transformer 包含两个阶段:
- Encoder(for Embedding):
- 输入一个 Sequence:
I arrived at the ... - 通过 Word2Vec 或其他 Word embedding 算法得到所有 Word vectors
- 每个 Word vector 之间互相做 Attention
- 经过 n 层 Attention
- 输出一个 Embedding sequence
- 输入一个 Sequence:
- Decoder(for Prediction):
- 为 Decoder 输入一个表示开始的 Token:
start - Encoder 的输出 Sequence 的每个结点分别与该 Token 做 Attention
- 经过 n 层 Attention,预测出下一个词:
Je Je与 Decoder 在此之前产生的所有东西(start)以及 Encoder 的输出做 Attention- 经过 n 层 Attention,预测出下一个词:
suis - 同理,
suis与 Decoder 在此之前产生的所有东西(start,Je)以及 Encoder 的输出做 Attention - 直到翻译完成
- 为 Decoder 输入一个表示开始的 Token:
BERT 的训练策略
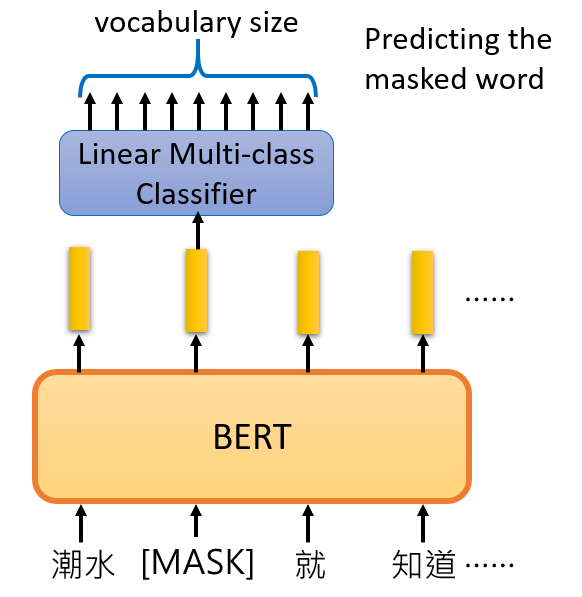
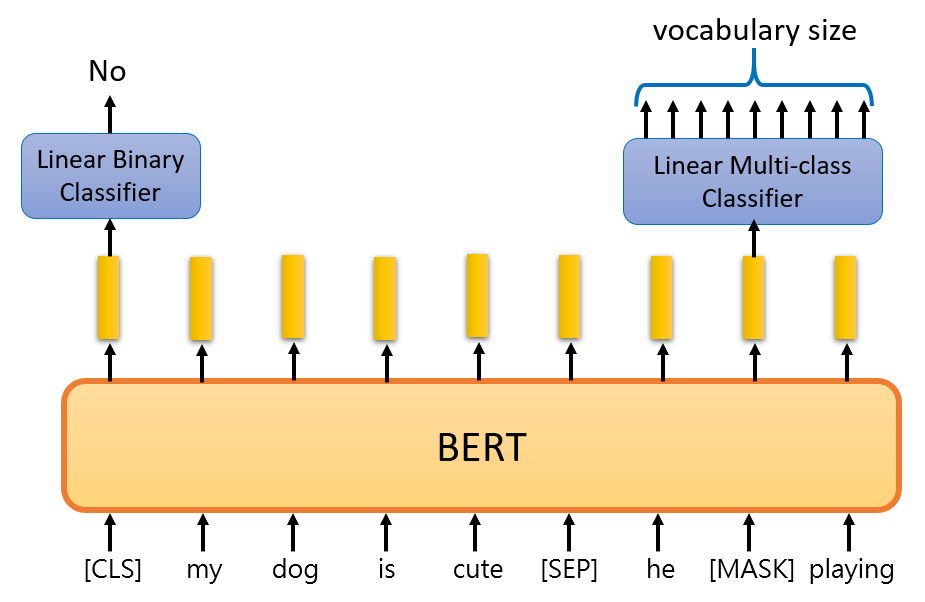
Masked LM
在训练一个语言模型时,我们常常将“预测下一个词”作为预测目标,但这点在 Bidirectional 的模型中是有限制的,比如:“The man went fishing by the bank of ______.”,为了克服这个问题,BERT 使用了一种叫做 Masked LM 的策略。
在将 Sequence 输入 BERT 之前,该 Sequence 中会有 15% 的词被替换为 [MASK] 这个 Token,然后模型尝试通过其他未被遮挡的单词来预测这个单词,这样的话,就需要在 Encoder 的输出之后加入一个简单的分类器,用来预测 [MASK] 位置上词汇表中每个单词出现的概率。如下图所示:
Next Sentence Prediction (NSP)
在 BERT 训练过程中使用的第二个策略叫做 Next Sentence Prediction,即输入两句话,预测后一句话在语义上与前一句话是否相接。BERT 中使用 [SEP] 这个 Token 来表示两句话的边界,使用 [CLS] 这个 Token 放在第一句话的最前面表示要进行“前后文预测”,并在此位置输出 NSP 的预测结果(简单的二分类:Yes|No)。如下图所示:
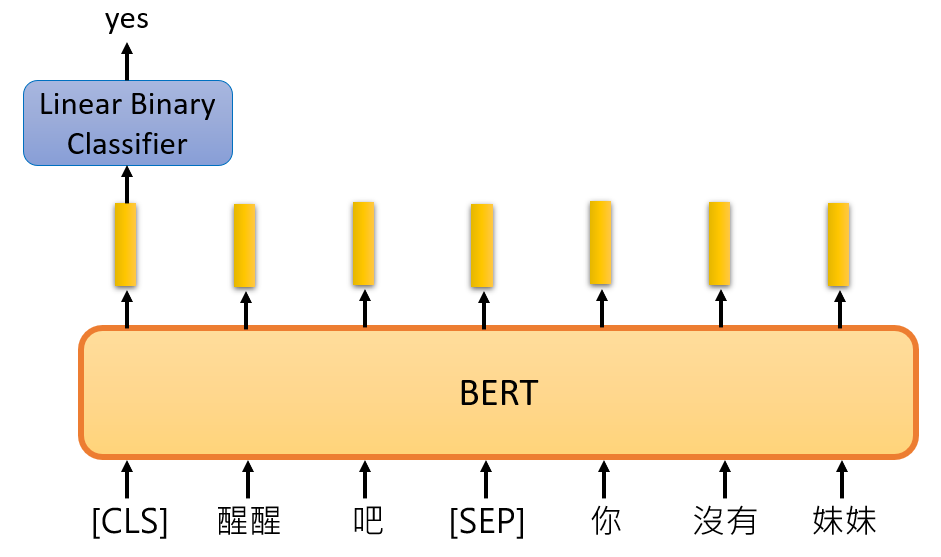
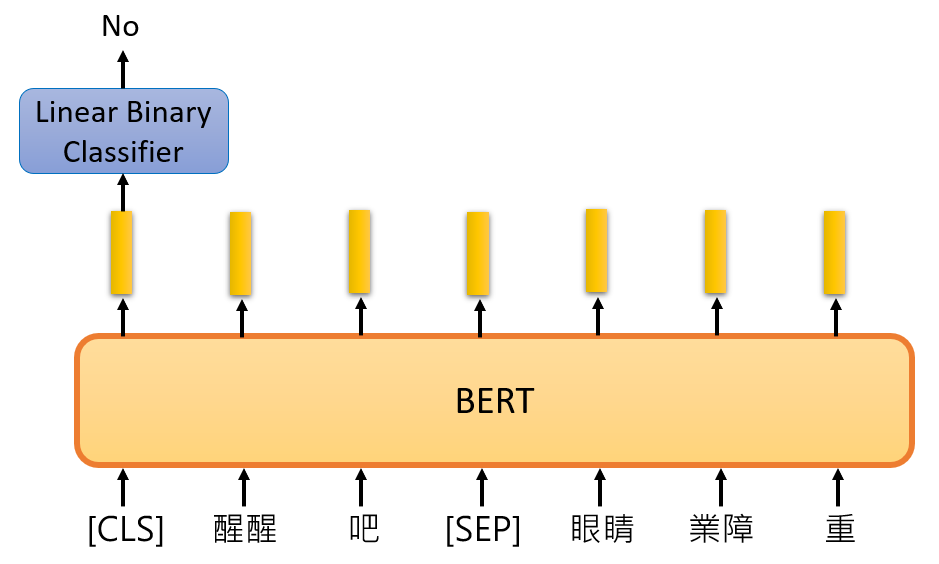
既然有两种训练策略,那么啥时候该用哪种策略呢?
BERT 就很直接:我全都要! 同时使用 Masked LM 和 NSP:
BERT 如何使用
Document Classification
文档分类(Document Classification)是指对输入的一个句子,或一篇文档做分类。其中又包括情感分析(Sentiment Analysis)这一任务。
Input:一个句子、表示分类的 Token:
[CLS]
Output:该句子的类别预测结果
其中分类器从头开始训练,BERT 可以微调。

Slot filling、NER
Slot filling 算是广义的 命名体识别(Named Entity Recognition,NER),即给句子中每个单词的类别进行分类,比如“时间”、“地点”等。
Input:一个句子、表示分类的 Token:
[CLS]
Output:每个词的类别
Natural Language Inference
自然语言推断(Natural Language Inference)是指给定一个“前提”(Premise)和一个“假设”(Hypothesis),让模型去预测在这个“前提”下的“假设”是否成立。
Input:两个句子、用于分割两句的 Token:
[SEP]、表示分类的 Token:[CLS]
Output:“假设”是否成立(T/F/unknown)

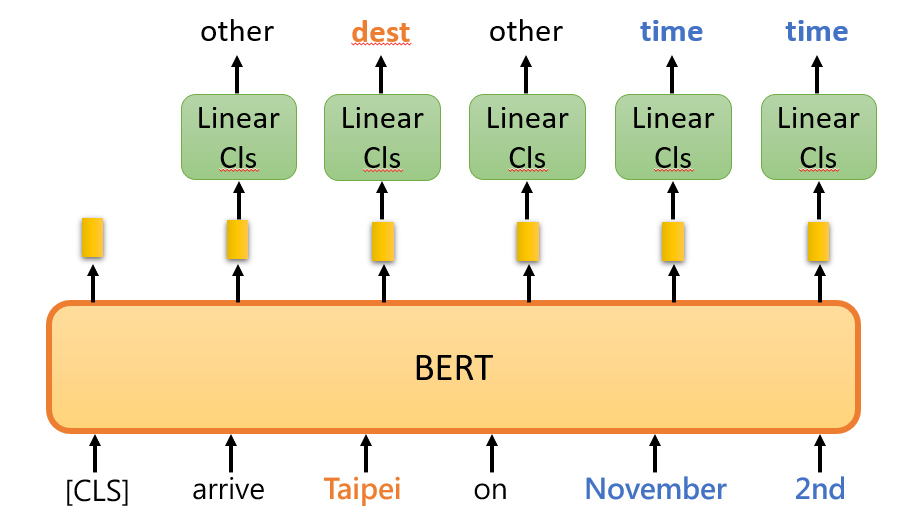
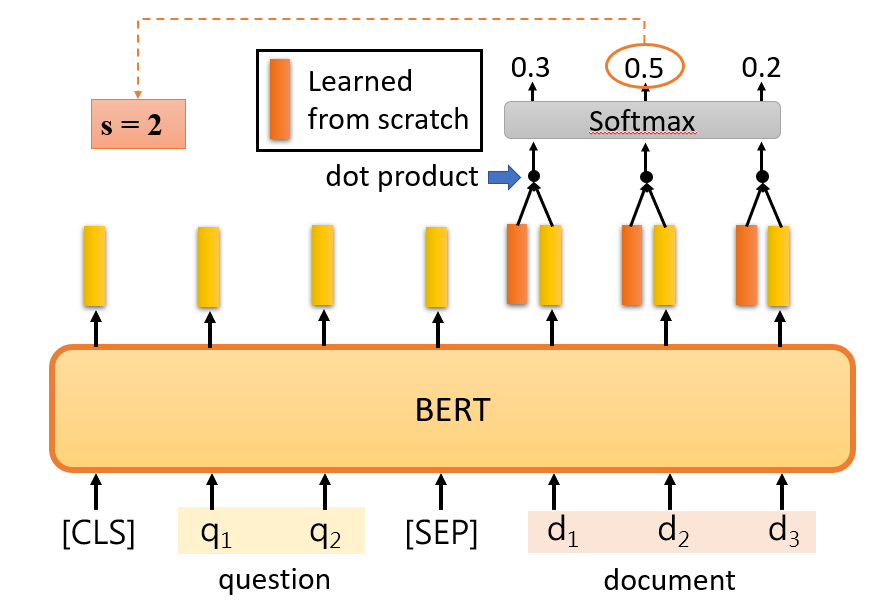
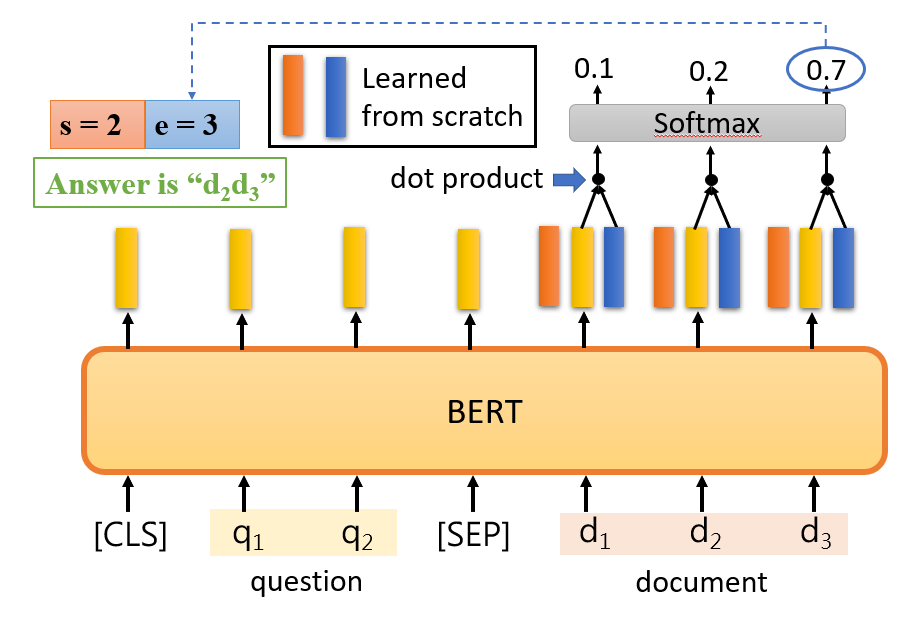
Extraction-based Question Answering
问答系统(Question Answering,QA)是指输入一段“文本”,并输入一个“问题”,让模型去预测出这个“问题”的“答案”。其中 Extraction-based 是指这个“答案”可以从给定的“文本”中提取出来。
Input:一个问题 Q、一段文本 D、用于分割两句的 Token:
[SEP]、表示分类的 Token:[CLS]
Output:两个整数 s 和 e(分别表示答案处于文本 D 中的起始 start 和结束 end 位置)
通过训练集学习出下图中橙色和蓝色矩形所示的 Embedding 表示,将它们分别与文本 D 中所提取出的 Word embedding 计算内积,然后通过一个 Softmax 运算,找出概率最高的那个词所处的位置,就分别表示答案位于文本 D 中的具体位置,其中橙色对应答案开始(Start,s)的位置,蓝色对应答案结束(End,e)的位置。
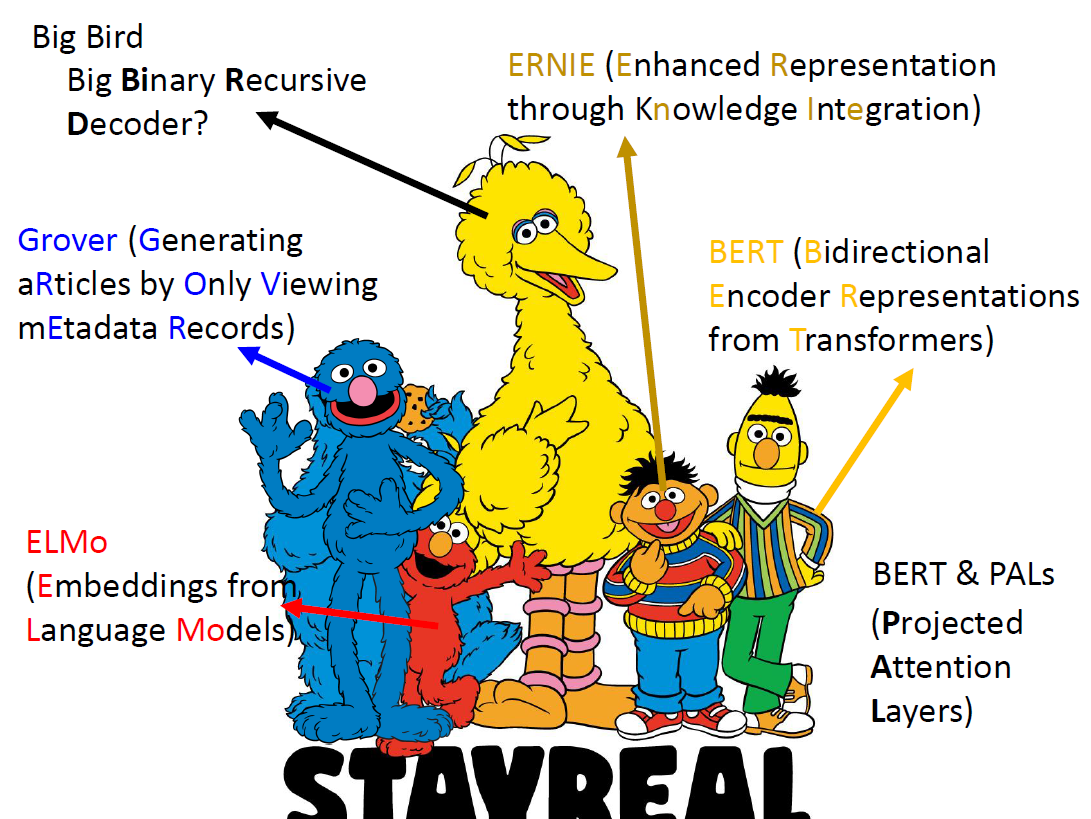
BERT 家族
还记得本文一开头的那张图片嘛?那是美国儿童电视节目《芝麻街》中主要角色的一张合照,可以看到,本文所介绍的 BERT 就是《芝麻街》中的黄色小人的名字,同样的,红色小人叫做 ELMO,橙色小人叫做 ERNIE,蓝色小人叫做 Grover,他们分别对应 NLP 中的三个语言模型:ELMo(Embeddings from Language Models)、ERNIE(Enhanced Representation through Knowledge Integration)以及 Grover(Generating aRticles by Only Viewing mEtadata Records)。
奇了,不知道为什么 NLP 研究者们这么喜欢《芝麻街》.

ELMo
ELMo(Embeddings from Language Models)是一种基于双向 RNN 的语言模型,如下图所示:
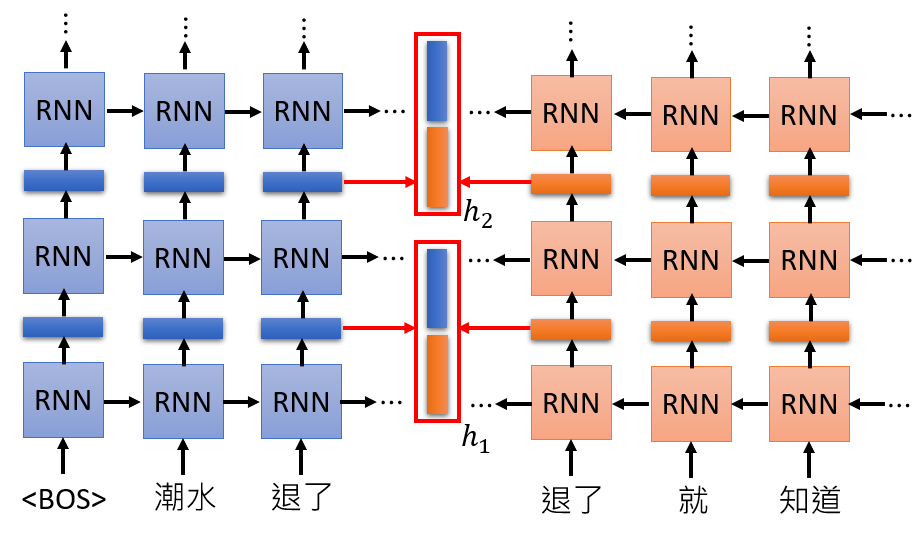
上图展示的是两层 ELMo 的示意图,可以看到,每一层对于每个输入,都会输出两个 Embedding 向量(一个正向 Embedding,一个反向 Embedding),ELMo 直接将它们 Concat 起来。
那么如果要堆叠多层 RNN 的话该怎么办呢,对于一个输入 Word,每一层都会输出一个 Embedding,n 层 RNN 就会生成 n 个 Embedding,不就越来越多了嘛?别急,ELMo 说:我全都要!

对于一个两层 ELMo 来说,它会将这两层的两个 Embedding 通过某种操作二合一:
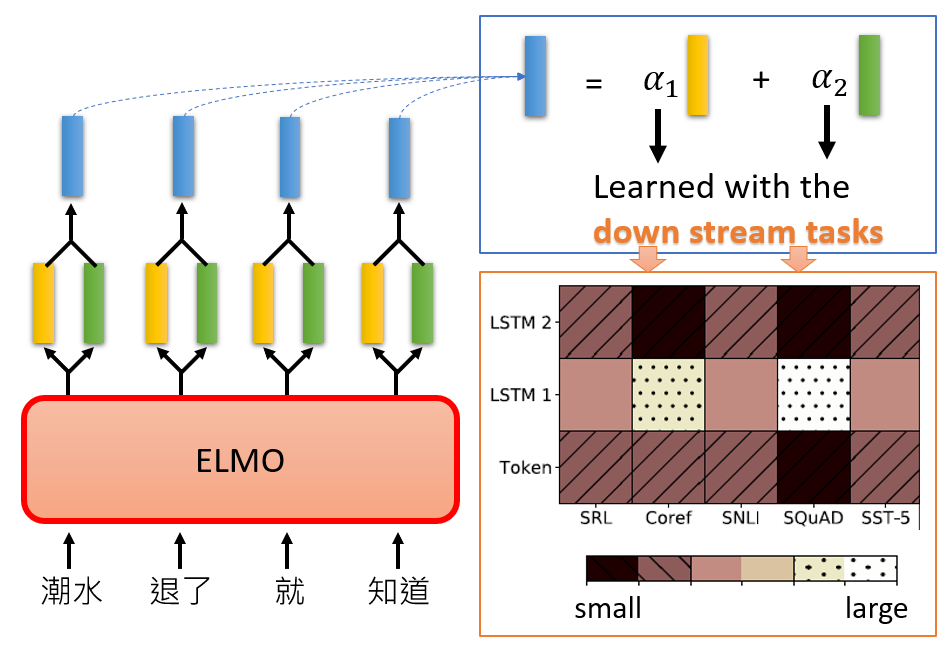
上图中蓝色 Embedding 即为合成的结果,可以看到,实际上就是一个加权平均,其中值得关注的是这两个权重 和 是如何得来的。ELMo 中定义,这两个权重根据不同的下游任务而有所不同,如图中橙色框内所示,“Token”、“LSTM1”和“LSTM2”分别表示“输入数据的 Word vector”、“第一层 LSTM 的输出”以及“第二层 LSTM 的输出”,我们举个例子,比如对于“Coref”以及“SQuAD”这两个任务,他们对“第一层 LSTM 的输出”更看重,而“第二层 LSTM 的输出”对它们几乎无用,其他任务以此类推。
ERNIE
ERNIE(Enhanced Representation through Knowledge Integration)是由百度飞桨 PaddlePaddle 团队提出的,一种专门针对中文的语义模型。
用一张图来说明 ERNIE 和 BERT 的区别:
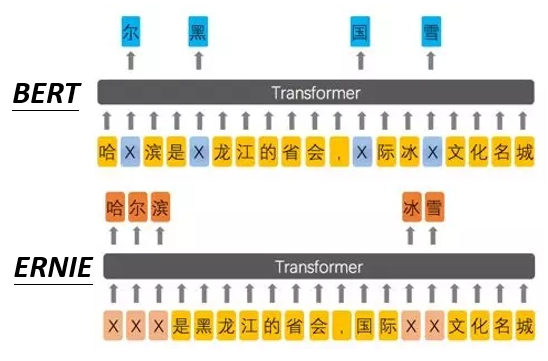
由于 BERT 中的 [MASK] 机制是针对于字来说的,而中文中有非常多的词组,如果只盖掉其中某个字,那么很容易就能猜出来,因此,ERNIE 选择盖掉整个词组,这样才更合理。
- Github Repo:ERNIE
Grover
此处不做介绍。
GPT
GPT(Generative Pre-Training)虽然不是《芝麻街》中的人物,但它经常被拿来与 BERT 进行比较,因此这边也顺带提一下,它和GPT-2都是由 OpenAI 团队提出的一种语义模型,与 BERT 相对,它实际上是 Transformer 的 Decoder 部分。而这个模型的卖点呢,就是 —————— 大大大大大。详情可参考原论文,这里不做详细介绍。

可以看到,ELMo 模型只有 94MB,BERT 模型有340MB,而 GPT-2 模型达到了 1542MB的容量,这对于一个语义模型来说已经非常巨大了。
实践
Reference
[1] Video: BERT Research Series
[2] Video: BERT and its family - Introduction and Fine-tune
[3] Video: ELMO, BERT, GPT
[4] Video: Transformer
[5] Blog Post: Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
[6] 知乎专栏: ERNIE