什么是 Azure Text to Speech
Azure Text to Speech 官网:https://azure.microsoft.com/en-gb/services/cognitive-services/text-to-speech/
Azure Text to Speech 简称 TTS,是 Azure Cognitive Service 中的一项 Speech Service,可以用 Azure 中已经预训练好的语言模型或者自定义的模型来将文本转化为独具特色的语音,常用于 ChatBot 或者智能语音客服中的 response 阶段,将用户所寻求的回答用语音的方式呈现出来。
Azure Text to Speech 具有以下特点:
- 流利自然的语音输出,符合人类听觉习惯
- 支持200多种人物语音和超过50多种语言:Language support
- 可自定义输出语音:Custom Voice
- 方便调整输出格式:语速、音调、口音等
支持的编程语言
与 STT 一样,TTS 同样支持以下几种语言:
- C#
- C++
- Go
- Java
- JavaScript
- Objective-C / Swift
- Python
- REST API
快速入门
DEMO
https://reborntts2.azurewebsites.net/apidocs/
相关资源
此处我们以 C# 为例,其他语言可从对应的官方 Github Repo 中找到相应的代码
- Official Tutorial:Microsoft-Doc
- Source Code:Github-Repo
- 根据 Tutorial 自己实现的 Sample Code:DevOps-Repo
输出方式
Azure Text to Speech 支持两种数据输出的方式:
- 输出到麦克风:不指定
AudioConfig即可从麦克风直接播放 - 输出到音频文件(可以是 .wav/.mp3):
AudioConfig.FromWavFileOutput("PathToFile.wav"),格式可通过config.SetSpeechSynthesisOutputFormat()方法来进行修改,支持的格式类型可查看:Audio Format
通过SSML自定义语音特征
Speech Synthesis Markup Language (SSML) 语音合成标记语言,允许我们微调TTS输出语音的音节、发音、语速、音量等特征。
详细 SSML 的配置选项可参考:SSML-Doc
一个简单的 SSML 示例如下:
复制的话记得将“< /”中间的空格删掉,这里加上空格是为了防止浏览器将其误渲染。
1 | <speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US"> |
其中
我们运行程序,试听一下输出的音频,会感觉到语速过快,我们可以通过添加一个
复制的话记得将“< /”中间的空格删掉,这里加上空格是为了防止浏览器将其误渲染。
1 | <speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US"> |
神经语言(Neural Voices)
神经语言(Neural Voices) 是通过深度神经网络来生成的语言,和真人说话的声音和语调更加相似,随着类人的自然韵律和字词的清晰发音,用户在与 AI 系统交互时,神经语音显著减轻了听力疲劳。
我们通过修改 SSML 文件的 name 属性来选择一种支持的神经语言(Support List),并通过添加 cheerful 语气,我们也可以试试 customerservice 或者 chat 来听听有何不同。
复制的话记得将“< /”中间的空格删掉,这里加上空格是为了防止浏览器将其误渲染。
1 | <speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang="en-US"> |
Custom Voice
Custom Voice 是 Azure 提供的用于自定义语音的一个平台。使用 Custom Voice 可以为客户的自有品牌创建可识别的独一无二的语音,我们只需准备好几个音频文件和关联的转录文本即可实现,通过用户友好型 UI,对于没有 AI 相关背景的用户也能流畅使用。
下图展示了 Custom Voice 的 Workflow:
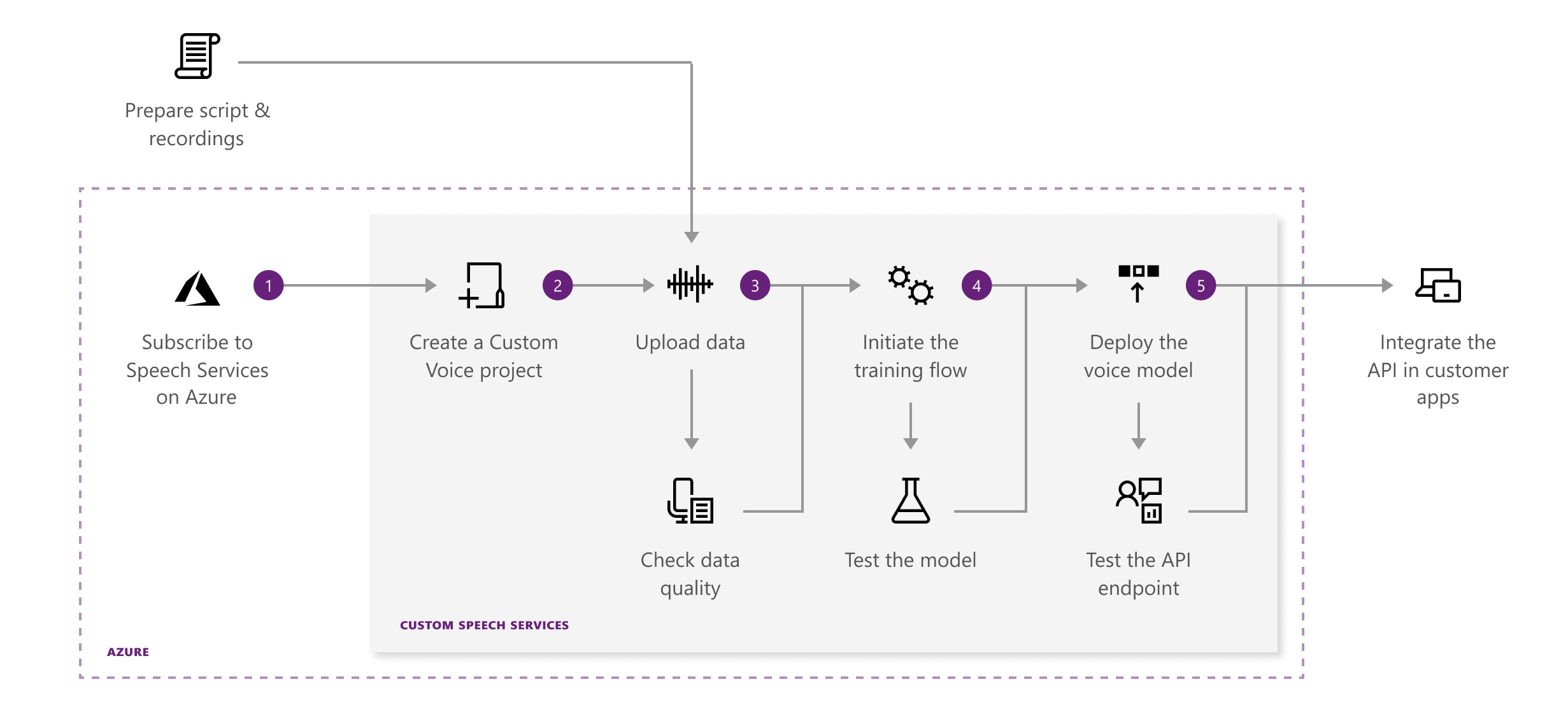
Custom Voice 提供了如下功能模块:

- Data:用于数据集的上传,支持单音频用于测试,或者音频+人工标注的文本用于训练
- Model:可直接用 Azure 自带的模型,或者 customized 的模型进行测试
- Endpoint:将训练好的模型进行部署,以便调用
Data
支持的数据类型:
Custom Voice 支持三种类型的数据,详情可查看(Link):
- 短音频(≤ 15s)和对应的文本
- 长音频(≥ 20s)和对应的文本
- 单独的音频文件
- 对于第二种数据类型,Custom Voice 会在后台自动对其进行切分,将其变成第一种类型
- 对于第三种数据类型,Custom Voice 会在后台自动进行转录生成对应的文本,若音频太长,还会自动进行分割,将其变成第一种类型
- 以上几种类型都要求将所有的音频打包成一个zip文件,所有的转录文本打包成一个zip文件,通过文件名来进行音频和文本的配对。
如下图所示,我们将一个 44s 长度的音频按照第二种方式上传后,Custom Voice 会将其自动分成合适长度的 4 段短音频,并会计算相应的指标,用作对于该数据集质量的评估:
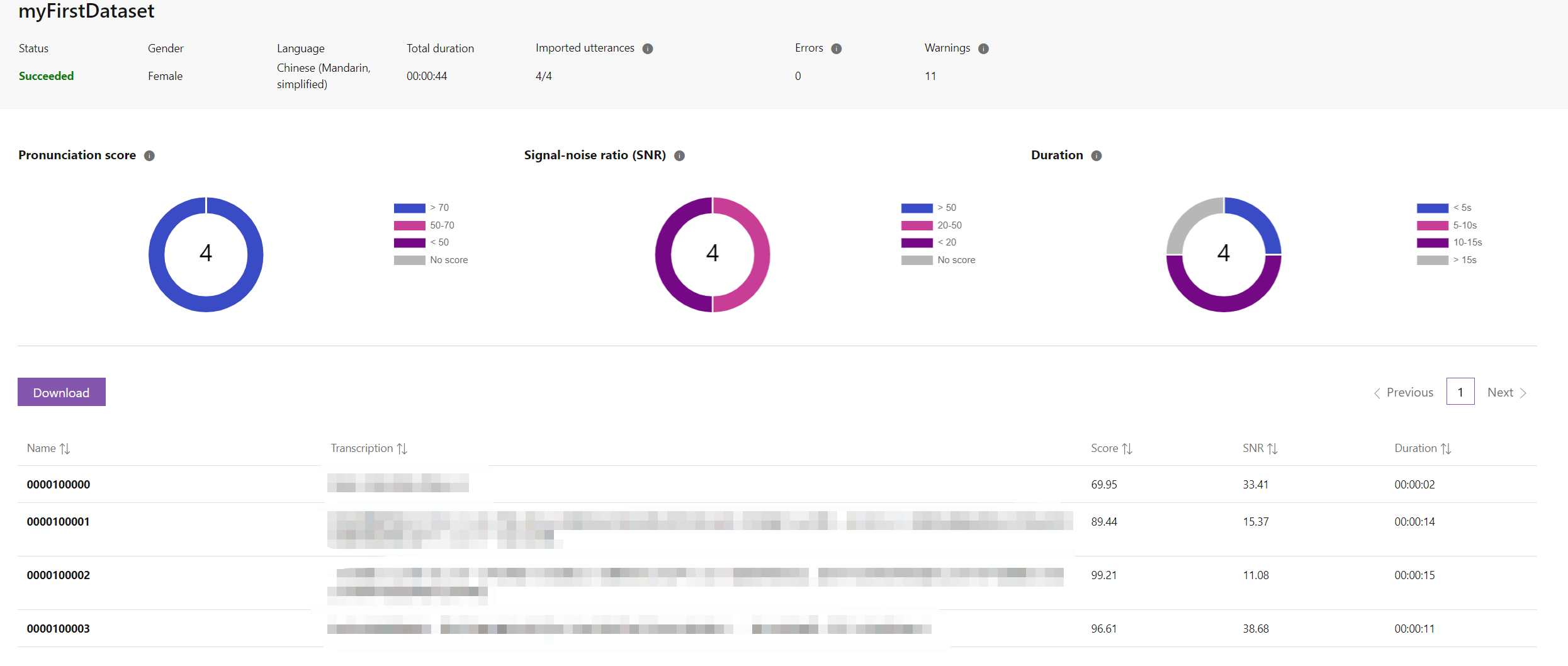
各指标如下:
- Pronunciation score:发音得分,用来评判发音是否标准,越高越好,尽量需要保证 ≥ 70
- Signal-noise ratio (SNR):信噪比,声音信号与噪声的比值,越大越好,尽量需要保证 ≥ 20
- Duration:音频时长,尽量需要保证 ≤ 15s
Model
Model 模块包含如下三个阶段:
- Training
对于 en-US 和 zh-CN 语言,可以使用任意数量的样本来训练模型;对于其他语言,至少需要 2000 个样本才能训练。 - Testing
训练完后,系统会自动生成100个随机样本进行测试,可以点进去听一下效果。 - deployment
如果效果合适,则可将模型部署,便于代码中进行调用
Endpoint
模型部署完后会生成一个 endpoint 节点,参照下图所示的指引即可使用该模型生成语音。
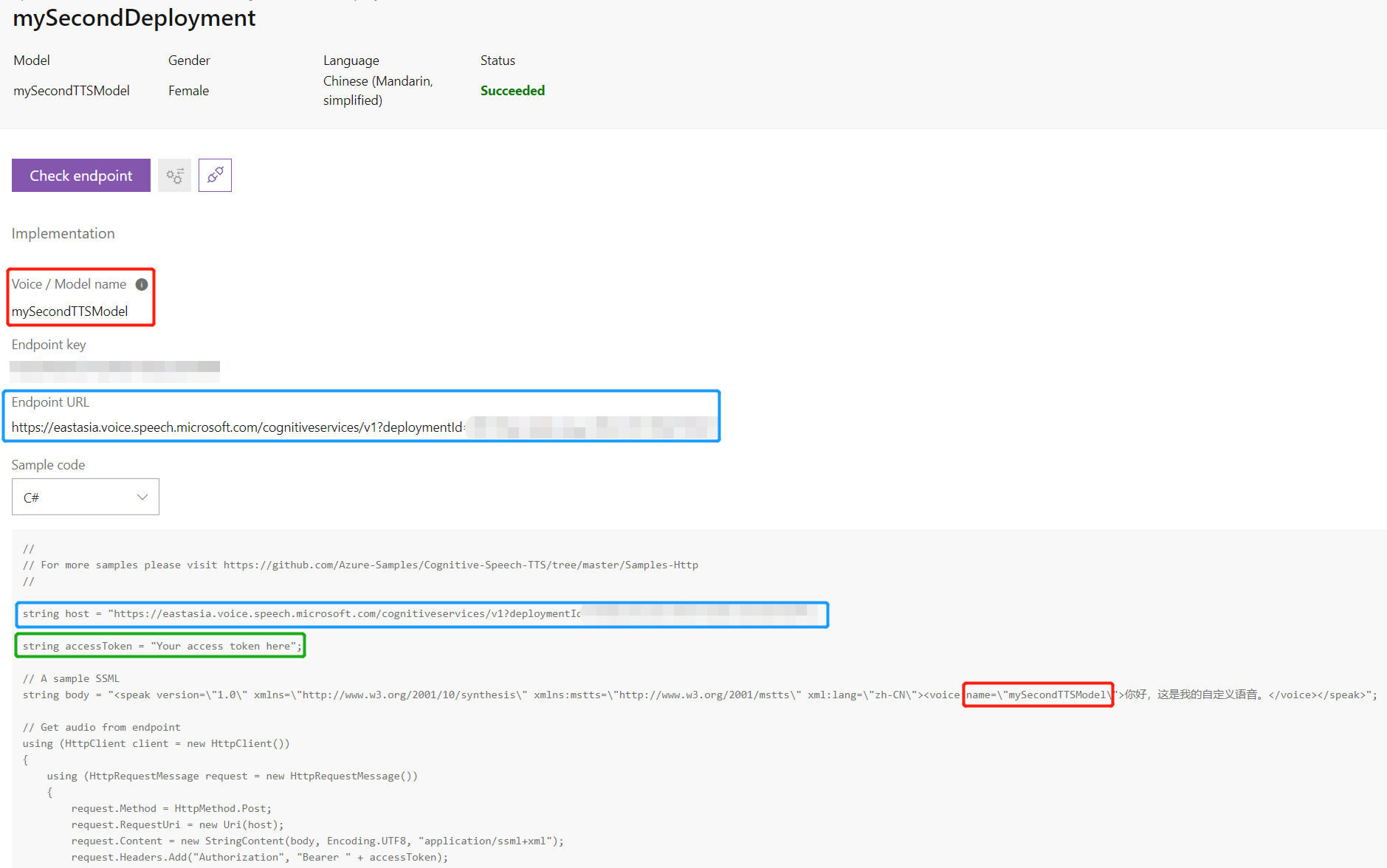
值得注意的是,代码中用到了一个叫做 accessToken 的变量,我们需要手动去请求(参考 Doc),所以创建了一个 Authentication 类用来请求 accessToken,完整的 C# 代码如下:
1 | public class Authentication |
其中,
- [MY-SUBSCRIPTION-KEY]:替换为自己创建的 Cognitive Service resource 的 key
- [MY-ENDPOINT-URL]:替换为自己生成的
Endpoint URL - [MY-MODEL-NAME]:替换为自己生成的
Voice / Model name - [MY-RESOURCE-NAME]:替换为自己创建的 Cognitive Service resource 的 name
- [MY-REGION]:替换为自己的 resource 所在的 region
- string body:将
<后面的空格删去,此处加上空格是为了避免浏览器将 xml 语法误渲染导致的显示不全






